
Mzdy v IT. Kdy si říct o peníze a o kolik.
Díky veřejné databázi Českého statistického úřadu můžete zjistit, kdy je ta nejlepší chvíle si říct o vyšší plat (nebo mzdu). A také, o kolik procent si říct navíc. Pokud budete vyzbrojeni takovými informacemi, nic vám už nebrání zajít za šéfem a vyšší mzdu dostat.
Porozumění trhu práce je dobrou příležitostí k uplatnění statistického programovacího jazyka R.
Erko nám umožňuje několik věcí:
- pomocí balíčku czso přímo přistupovat k Veřejné databázi Českého statistického úřadu
- na získaná data uplatnit základní (či pokročilé :) modelovací techniky
- a konečně o získané informaci podat zprávu graficky
V rámci modelu budu uvažovat geometrickou posloupnost – růst mezd o stálé procento. Tento vztah odpovídá ekonomické teorii lépe, než závislost lineární (růst mezd o stálou částku).
Prvním krokem je načtení knihoven a akvizice surových dat. Základním vstupem pro analýzu bude vstupem standardní datová sada číslo 110079
– Zaměstnanci a průměrné hrubé měsíční mzdy podle odvětví. Dataset má kvartální periodu.
library(czso) # protože staťák...
library(tidyverse) # kvůli dplyr & ggplot2
library(zoo) # pro konverzi datumů / kvartály v letech
# načtu dataset s id 110079 = Zaměstnanci a průměrné hrubé měsíční mzdy podle odvětví
raw_mzdy <- czso::czso_get_table("110079")
Když jsme datovou sadu načetli, tak se na hrubo seznámíme s její strukturou a obsahem:
glimpse(raw_mzdy)
## Rows: 6,880
## Columns: 16
## $ idhod <chr> "741383707", "741383708", "741383709", "741383713", "7413…
## $ hodnota <dbl> 23546, 24057, 27242, 22691, 24135, 24635, 27830, 10640, 1…
## $ stapro_kod <chr> "5958", "5958", "5958", "5958", "5958", "5958", "5958", "…
## $ mj_cis <chr> "78", "78", "78", "78", "78", "78", "78", "78", "78", "78…
## $ mj_kod <chr> "00200", "00200", "00200", "00200", "00200", "00200", "00…
## $ typosoby_kod <chr> "200", "200", "200", "200", "200", "200", "200", "200", "…
## $ odvetvi_cis <chr> "5103", "5103", "5103", "5103", "5103", "5103", "5103", "…
## $ odvetvi_kod <chr> "P", "P", "P", "P", "P", "P", "P", "Q", "Q", "H", "H", "H…
## $ rok <int> 2012, 2012, 2012, 2013, 2013, 2013, 2013, 2000, 2000, 200…
## $ ctvrtletí <chr> "2", "3", "4", "1", "2", "3", "4", "1", "2", "1", "2", "3…
## $ uzemi_cis <chr> "97", "97", "97", "97", "97", "97", "97", "97", "97", "97…
## $ uzemi_kod <chr> "19", "19", "19", "19", "19", "19", "19", "19", "19", "19…
## $ stapro_txt <chr> "Průměrná hrubá mzda na zaměstnance", "Průměrná hrubá mzd…
## $ mj_txt <chr> "Kč", "Kč", "Kč", "Kč", "Kč", "Kč", "Kč", "Kč", "Kč", "Kč…
## $ typosoby_txt <chr> "přepočtený", "přepočtený", "přepočtený", "přepočtený", "…
## $ odvetvi_txt <chr> "Vzdělávání", "Vzdělávání", "Vzdělávání", "Vzdělávání", "…
Dataset obsahuje v normalizované formě více statistických veličin (mzdu a počet zaměstnanců) ve dvou dimenzích (surová data, a jejich přepočet na plné úvazky / FTEs = Full Time Employees). Pro eliminaci duplicit bude před vlastním modelováním nutno nastavit filtr.
Mzdy jsou evidované po odvětvích; pro zjednodušení se v úvodní vizualizaci zaměříme na tři, u kterých je větší pravděpodobnost využití technik jazyka R: ICT pracovníky, vědecké pracovníky a učitele a učitelky.
# odliji stranou čistší dataset
clean_mzdy <- raw_mzdy %>%
filter(stapro_kod == '5958' # průměrná mzda / zahazuju počty zaměstnanců
& typosoby_kod == '200'# přepočet na ekvivalent plného úvazku
& odvetvi_kod %in% c('P', 'M', 'J')) %>% # tři vybrané sektory
# konverze konvence z roku + čtvrtletí na prosté datum (první den kvartálu)
mutate(datum = as.Date(as.yearqtr(paste0(rok, "Q", ctvrtletí))))
# základní overview graficky
ggplot(data = clean_mzdy, aes(x = datum, y = hodnota, color = odvetvi_txt)) +
geom_point() +
scale_y_continuous(limits = c(0, 70000),
labels = scales::dollar_format(prefix = "",
suffix = " Kč",
big.mark = " ")) +
labs(title = "Průměrná hrubá měsíční mzda v čase",
color = "Sektor podle ČSÚ") +
theme_minimal() +
theme(axis.title = element_blank(),
plot.title = element_text(hjust = 1/2,
size = 14),
legend.position = c(0.795, 0.175),
legend.direction = "vertical",
legend.title = element_text(hjust = 1/2),
legend.background = element_rect(fill = "white",
color = NA))
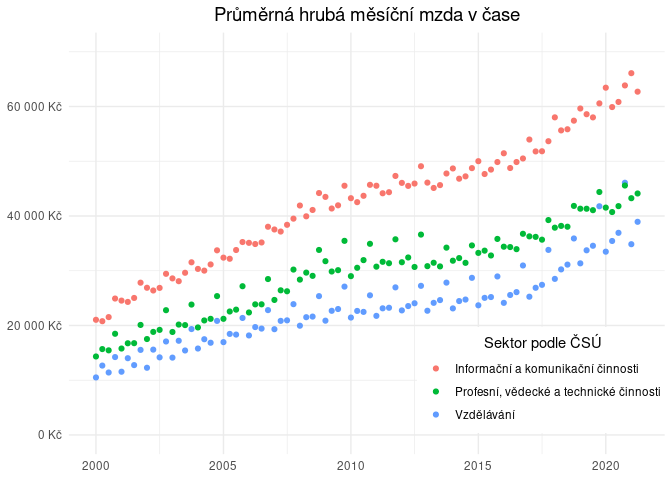
Z grafu můžeme vypozorovat tři fáze cyklu mezd:
- růst mezi rokem 2000 (počátek známé historie) a rokem 2010
- spíše stagnaci mezi lety 2010 a 2015
- opětovný růst od roku 2015 dále
Pro vlastní model zvolíme období růstu po roce 2015, kterému můžeme říkat Éra Andreje Babiše – a podle toho, jak moc panu premiérovi fandíme, budeme uvažovat, že to byl právě on, kdo:
- konečně zařídil peníze pro naše lidi (😀)
- nezodpovědně roztočil inflační spirálu (😦)
Na další práci s modelem už náš názor na pana premiéra vliv mít nebude.
Pro model vybereme jeden obor, a sice ICT pracovníky neboli ajťáky.
# připravíme podkladový dataset "ajťáci v časech Andreje Babiše" pro trénink modelu
era_babise <- clean_mzdy %>%
filter(datum >= as.Date("2015-01-01")
& odvetvi_kod == 'J') %>% # pouze ICT sektor
arrange(datum) %>% # setřídím dle data / pro jistotu, kvůli sekvenci v příštím kroku
mutate(sekvence = 1:n()) # pořadové číslo kvartálu v rámci Éry A. B.
Pro vlastní matematický model budeme uvažovat geometrickou posloupnost - jinými slovy budeme předpokládat, že mzdy ajťáků vzrostou z kvartálu na kvartál pokaždé o stejné procento.
Taková posloupnost se dá popsat vzorcem a * (1 + r) ^ sekvence, kde a je počáteční hodnota (mzda v IT na začátku éry Andreje Babiše), r je míra růstu z kvartálu na kvartál a sekvence je pořadové číslo kvartálu v rámci éry Andreje Babiše.
Pro nalezení konkrétních hodnot parametrů a a r použijeme techniku nejmenších čtverců, konkrétně funkci stats::nls(). Povinnými vstupy jsou podkladová data a vzorec očekávané závislosti v tildové notaci. Pro rychlejší konvergenci modelu můžeme doplnit iniciální hodnoty parametrů.
# natrénujeme matematický model přes stats::nls()
matematicky_model <- nls(hodnota ~ a * (1 + r)^sekvence, # vzorec, v tildové notaci
data = era_babise, # podkladová data
# vstupní odkad parametrů / odhad přes palec
start = list(a = 50000,
r = .01))
# shrnutí modelu - hodnoty parametrů, významnost &c.
summary(matematicky_model)
##
## Formula: hodnota ~ a * (1 + r)^sekvence
##
## Parameters:
## Estimate Std. Error t value Pr(>|t|)
## a 4.703e+04 5.795e+02 81.14 < 2e-16 ***
## r 1.231e-02 7.507e-04 16.40 1.53e-14 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1571 on 24 degrees of freedom
##
## Number of iterations to convergence: 3
## Achieved convergence tolerance: 3.634e-08
Model je jednoduchý a teoreticky dobře podložený, takže nás nepřekvapí že pro oba hledané parametry vyšly odhady jako statisticky významné.
- modelová mzda v IT sektoru na počátku éry nám vyšla 47 025 Kč; pro kontext: skutečnost Q4 2014 byla 48 744 Kč, což představuje rozdíl 3.5%.
- modelové tempo kvartálního růstu hrubých mezd v ICT nám vyšlo 1.23%.
Získaný model můžeme snadno protáhnout do budoucna, a porovnat graficky se skutečností:
# podklad pro uplatnění matematického modelu
jiny_cas <- data.frame(sekvence = 0:30) %>%
mutate(datum = as.Date("2015-01-01") + months(3 * sekvence))
# predikce - uplatnění matematického modelu na nový vstup
jiny_cas$hodnota <- predict(matematicky_model,
newdata = jiny_cas)
# grafické podání zprávy o skutečnosti a modelu
ggplot() +
geom_line(data = jiny_cas, aes(x = datum,
y = hodnota),
color = "red") +
geom_point(data = era_babise, aes(x = datum,
y = hodnota),
pch = 4, color = "gray50") +
scale_y_continuous(limits = c(40, 70) * 1000, # menší rozsah osy, ať vyniknou epsilonky
labels = scales::dollar_format(prefix = "",
suffix = " Kč",
big.mark = " ")) +
labs(title = "Model a skutečnost průměrné mzdy v českém ICT sektoru v čase") +
theme_minimal() +
theme(axis.title = element_blank(),
plot.title = element_text(hjust = 1/2,
size = 14))
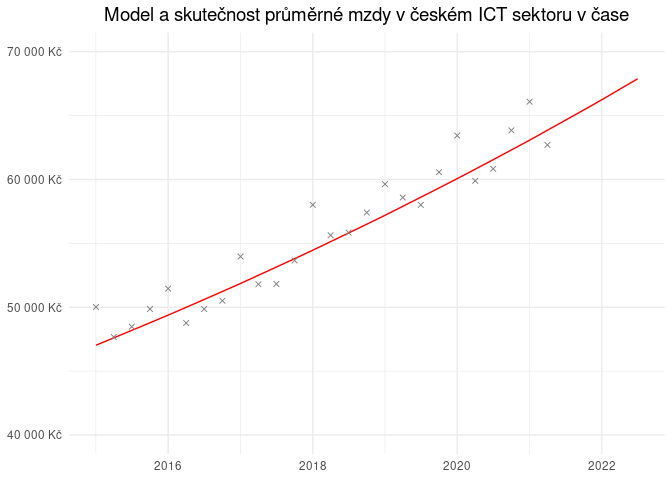
Vidíme, že model aproximuje skutečnost poměrně přesně; největší rozdíly jsou v prvních kvartálech roku, kdy je výrazná sezónnost (v reálném světě jí táhnou v tomto čtvrtletí vyplácené roční odměny, což je vlastnost kterou v rámci modelu neuvažujeme).
Když jsme model připravili, tak je čas ho použít. Obecně se nabízí dvě možnosti uplatnění:
- předpověď průměrné mzdy v budoucnu (po anglicku prediction)
- porozumění obecné problematice růstu mezd (po anglicku inference)
První bod bude relevantní jen pro někoho – ideálně průměrná mzda je umělý konstrukt, za který nikdo reálně nepracuje – ale druhý bod je zajímavější.
Čeští ajťáci si mohou snadno porovnat realitu změny svého platu s trhem jako celkem. Pokud rostou pod trhem, tak svoji relativní pozici v poli všech ICT zaměstnanců ztrácí; pokud rostou nad trhem, tak se v pelotonu posunují dopředu.
České konvence pracovního trhu nepočítají s kvartální úpravou mezd, obvyklejší je revize roční; očekávanou výši ročního nárůstu ze získané hodnoty koeficientu r získáme snadno.
# očekávaný roční nárůst mezd z titulu inflace
(1 + coef(matematicky_model)[["r"]]) ^ 4 - 1
## [1] 0.05016941
Jinými slovy pro ideálně průměrnou IT pozici očekáváme každoroční navýšení o 5.02% čistě z titulu běhu času a posunu trhu jako celku - za to, že poběžíme na místě s Červenou královnou.
V některých kontextech není obvyklé automatické navyšování, a o lepší peníze si musí člověk říct. Což s sebou nese určité tření, a nejde to dělat příliš často – je tedy vhodnější méně časté navýšení o větší částku.
V takovém případě může být zajímavé vědět, kolik času zabere trhu kumulativní nárůst o určitou hodnotu – řekněme 10%. Odpověď na tuto otázku nám dá opět koeficient r našeho modelu, jen musíme použít logaritmy.
# čas v kvartálech pro nárůst tržní mzdy o 10%
log(1 + 10/100) / log(1 + coef(matematicky_model)[["r"]])
## [1] 7.788132
Jinými slovy ideálně průměrný ajťák může očekávat nárůst mzdy o 10% někdy mezi 7. a 8. kvartálem od počátku.
Příklad vývoje mezd v IT byl vědomě lehčího rázu; nicméně věřím, že jsem v jeho rámci předvedl jak lehkost, s jakou lze přistupovat k datům ČSÚ přímo z pohodlí vaší R Session, tak eleganci erkových modelovacích nástrojů a přesvědčivost grafických výstupů. QED.
Poprvé zveřejněno na www.jla-data.net/cze/mzdova-inflace-v-erku.

Mohlo by vás zajímat
Blog

Brzdí vás Excel? Vlastní datové aplikace rychle a bez programátorů.

Jak vytváříme jednoúčelové aplikace s pomocí AI

Aritmetický průměr vs. medián
Kurzy

Data Analytics Pass

SQL pro analytiky

SQL pro každý den

Programování ve VBA

Statistika v Excelu. Krok za krokem.
