
JupySQL: lepší SQL v Jupyteru
Mít SQL a Python pěkně pohromadě v jednom notebooku je sen mnoha datových analytiků. Naštěstí to už dávno není sen. Protože možností, jak pohodlně pracovat s SQL v Jupyteru je více.
Můžete si vyzkoušet např. tento.
V tomto článku se podíváme na rozšíření (jupyter extension) pro Jupyter Notebook a Jupyter Lab. Jmenuje se JupySQL. Sami autoři pro něj používají krátký a výstižný claim Lepší SQL v Jupyteru.
Proč SQL
SQL syntaxe je pro mnoho uživatelů příjemnější, než syntaxe Pythonu a Pandas.
Často je také efektivnější zpracovat dotaz přímo v databázi, než data stahovat do dataframu a pak nad ním provádět paměťově náročné operace.
Úplně nejlepší je, když můžete využít přednosti SQL a Pythonu na jednom místě, v Jupyter Notebooku. A přesně to nabízí JupySQL.
Hlavní výhody JupySQL
- Snadná práce s SQL v Jupyteru
- Podpora databází - všechny, které podporují Python Database API
- Podpora Pandas dataframe
- Základní vizualizace - využívá knihovnu Matplotlib
- Možnost využití parametrů - díky Jinja templates
Instalace
Potřebné knihovny nainstalujete přes pip.
Následující příklady využívají lokální databázi DuckDB. Proto si nainstalujte potřebnou knihovnu.
pip install jupysql duckdb-engine matplotlib
Pokud využíváte distribuci Anaconda, použijte conda.
conda install -c conda-forge jupysql duckdb-engine matplotlib
Aktivace Jupyter rozšíření
Vytvořte nový Jupyter notebook. Jednotlivé příklady pište do samostatných buněk.
- Nahrajte rozšíření JupySQL,
- nastavte automatický výstup do Pandas dataframe
- a vytvořte místní DuckDB databázi. Soubor se vytvoří v adresáři, ve kterém jste spustili Jupyter.
%load_ext sql
%config SqlMagic.autopandas = True
%sql duckdb:///./zoo.ddb
Načtení dat
DuckDB umí načítat data z lokálního a vzdáleného úložiště.
V následujícím příkladu načtete vzorová data o sponzoringu zvířat v pražské zoo, která jsou ve formátu CSV.
Z načtených dat se vytvoří tabulka zoo.
Všimněte si 2 magických příkazů:
%%time- Ukáže, jak dlouho trvalo vykonání příkazu.%%sql- Zbytek celé Jupyter buňky je chápán jako SQL a proto bude zpracován pomocí JupySQL.
%%time
%%sql
CREATE OR REPLACE TABLE zoo
AS
SELECT * FROM "https://www.lovelydata.cz/media/files/zoo.csv";

Zobrazení tabulek v databázi
JupySQL má několik šikovných příkazů. Například ten, který vypíše seznam tabulek v databázi.
%sqlcmd tables
| Name |
|---|
| zoo |
Zobrazení sloupců tabulky
Následující příkaz zobrazí strukturu (sloupce) tabulky zoo.
%sqlcmd columns --table zoo
| name | type | nullable | default | autoincrement | comment |
|---|---|---|---|---|---|
| id | BIGINT | True | None | False | None |
| nazev_cz | VARCHAR | True | None | False | None |
| nazev_en | VARCHAR | True | None | False | None |
| trida_cz | VARCHAR | True | None | False | None |
| cena | BIGINT | True | None | False | None |
| k_prohlidce | BIGINT | True | None | False | None |
Zobrazení souhrných informací o datech
Tento příkaz poskytne základní přehled o datech v tabulce zoo.
%sqlcmd profile --table zoo
Funguje podobně jako pandas
df.describe().
| id | nazev_cz | nazev_en | trida_cz | cena | k_prohlidce | |
|---|---|---|---|---|---|---|
| count | 513 | 513 | 513 | 513 | 513 | 513 |
| unique | 513 | 513 | 490 | 6 | 15 | 2 |
| top | nan | Tygr ussurijský | Ptáci | nan | nan | |
| freq | nan | 1 | 24 | 237 | nan | nan |
| mean | 793.0331 | nan | nan | nan | 3309.9415 | 0.8928 |
| std | 448.6972 | nan | nan | nan | 6333.2132 | 0.3094 |
| min | 7 | nan | nan | nan | 1000 | 0 |
| 25% | 381.0000 | nan | nan | nan | 1000.0000 | 1.0000 |
| 50% | 820.0000 | nan | nan | nan | 1500.0000 | 1.0000 |
| 75% | 1216.0000 | nan | nan | nan | 3000.0000 | 1.0000 |
| max | 1421 | nan | nan | nan | 50000 | 1 |
Zobrazení dat
Díky JupySQL můžete v Jupyteru používat SQL úplně stejně, jako v něm používáte např. Python.
Zobrazte vzorek pěti záznamů z právě načtených dat.
%%sql
FROM zoo
USING SAMPLE(5);
Všimněte si použití SQL friendly syntaxe. Pockud nezadáte
SELECT, DuckDB to chápe jakoSELECT *.
| id | nazev_cz | nazev_en | trida_cz | cena | k_prohlidce | |
|---|---|---|---|---|---|---|
| 0 | 1166 | Čejka australská | Masked lapwing | Ptáci | 1500 | 1 |
| 1 | 721 | Bičovec pestrý | Whip spider | Bezobratlí | 1000 | 1 |
| 2 | 1144 | Ovce tlustorohá | Bighorn sheep | Savci | 3000 | 1 |
| 3 | 91 | Volavčík člunozobý | Boat-billed heron | Ptáci | 2000 | 1 |
| 4 | 1411 | Kačka strakatá | Ptáci | 1000 | 1 |

Magic commands
JupySQL podporuje použití 2 typů kouzelných příkazy Jupyteru:
%sql- jednořádkový%%sql- celá buňka
Následující 2 příklady dělají totéž:
%sql FROM zoo LIMIT 3
%%sql
FROM zoo LIMIT 3
| id | nazev_cz | nazev_en | trida_cz | cena | k_prohlidce | |
|---|---|---|---|---|---|---|
| 0 | 7 | Šváb syčivý | Madagascar giant cockroach | Bezobratlí | 1000 | 1 |
| 1 | 8 | Pakobylka okřídlená | Pink-winged stick insect | Bezobratlí | 1000 | 1 |
| 2 | 16 | Tayra | Tayra | Savci | 5000 | 1 |
Počty zvířat podle tříd
Kolik je zvířat v jednotlivých třídách?
%%sql
FROM zoo
SELECT trida_cz, COUNT(*) AS "Počet zvířat"
GROUP BY 1
ORDER BY 2 DESC;
Opět, používáte friendly SQL a proto může být
SELECTaž za klauzulíFROM.
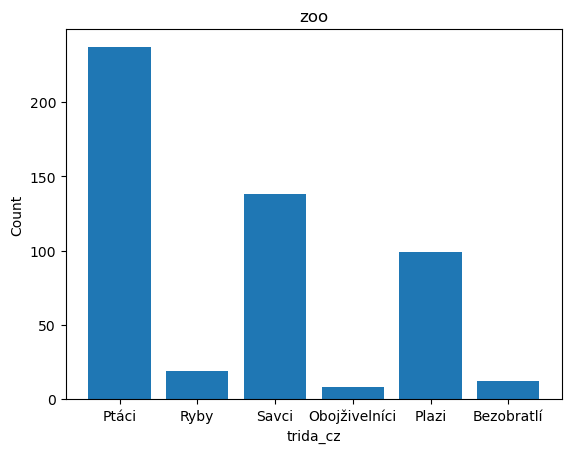
| trida_cz | Počet zvířat | |
|---|---|---|
| 0 | Ptáci | 237 |
| 1 | Savci | 138 |
| 2 | Plazi | 99 |
| 3 | Ryby | 19 |
| 4 | Bezobratlí | 12 |
| 5 | Obojživelníci | 8 |
Zobrazení sloupcového grafu
JupySQL využívá pro vizualizaci dat knihovnu matplotlib.
Nečekejte nijak bohatou nabídku grafů. Pro rychlou analýzu to ale v mnoha případech bude stačit. A hlavně, syntaxe není složitá.
Následující graf ukazuje počty zvířat v jednotlivých třídách. Stejně, jako předchozí SQL.
%sqlplot bar --table zoo --column trida_cz
Zobrazení histogramu
JupySQL nabízí zobrazení histogramu. Zkuste si přehled podle ceny rozdělený do 5 intervalů.
%sqlplot histogram --table zoo --column cena --bins 5
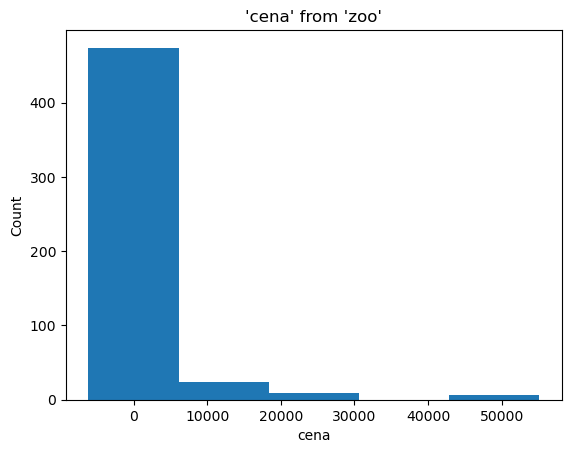
Vidíte, že zájemci o sponzorství zvířat se ve většině případů vejdou do deseti tisíc korun.
Zobrazení krabicového grafu
Pro lepší přehled podle ceny můžete využít krabicový graf (box plot).
%sqlplot boxplot --table zoo --column cena
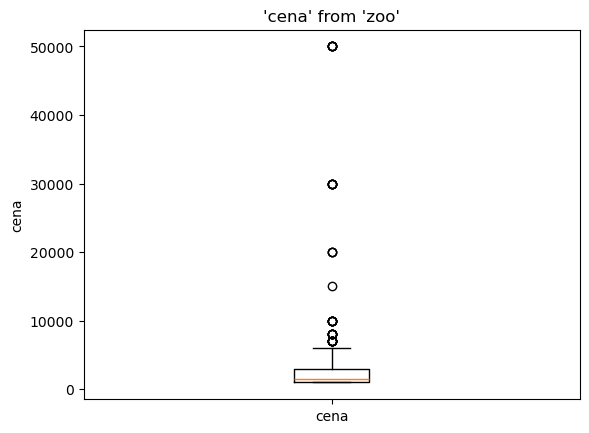
Výsledek je zkreslený záznamy, které mají vysokou cenu. Tyto záznamy potřebujete odfiltrovat.
Jednou z možností je použití databázové funkce quantile_disc, díky které nebudete brát v úvahu hodnoty nad 90. percentilem.
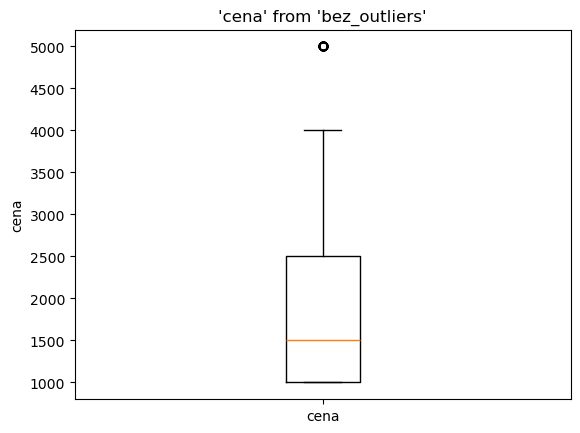
Zobrazení krabicového grafu - 90. percentil
Přehled podle ceny - záznamy pod 90. percentilem
%%sql --save bez_outliers --no-execute
FROM zoo
WHERE cena <= (SELECT quantile_disc(cena, 0.9) FROM zoo)
Všimněte si použití parametrů
--savea--no-execute.
--save: JupySQL si zapamatuje SQL, které můžete použít později.--no-execute: Dotaz se ihned nespustí, ale počká, až ho zavoláte. Např. při zobrazení krabicového grafu.
%sqlplot boxplot --table bez_outliers --column cena
Kontrola
Zkontrolujte pomocí agregačních funkcí:
%%sql
SELECT
avg(cena) AS "Průměr",
median(cena) AS "Medián",
mode(cena) AS "Modus (nejčastější výskyt)"
FROM zoo
| Průměr | Medián | Modus (nejčastější výskyt) | |
|---|---|---|---|
| 0 | 3309.94152 | 1500.0 | 1000 |

Zobrazení koláčového grafu
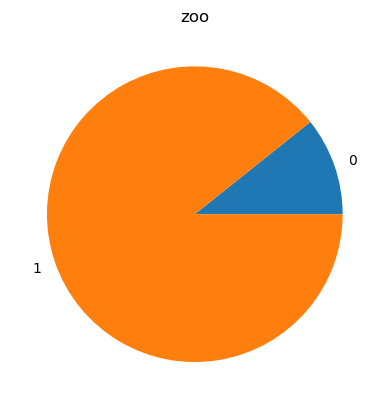
Koláčový graf (pie chart) je ideální pro zobrazení podílů jednotlivých kategorií.
Ale pozor - pouze v případě, že kategorií není příliš mnoho, ideálně do 5. Při vyšším počtu se stává nepřehledným.
Ne všechna zvířata si je možné prohlédnout. Jaký je jejich podíl?
%sqlplot pie --table zoo --column k_prohlidce
Uložení do Dataframe
JupySQL podporuje pandas. Výsledek SQL dotazu si tak můžete uložit do dataframu.
To otevírá široké možnosti, protože můžete snadno ve svém workflow kombinovat SQL, Python, pandas a další knihovny.
%%sql
df << FROM zoo
Export dataframe do Excelu
Z dataframu si pak data snadno uložíte, např. do Excelu.
df.to_excel("zoo.xlsx", index=False)

Mohlo by vás zajímat
Blog

Přestaňte obviňovat model, začněte klást lepší otázky

Brzdí vás Excel? Vlastní datové aplikace rychle a bez programátorů.

Jak vytváříme jednoúčelové aplikace s pomocí AI
Kurzy

Python - základy

Základy Tableau

Vizualizace dat v Canvě

Statistika v Excelu. Krok za krokem.

Excelentní Triky 1
